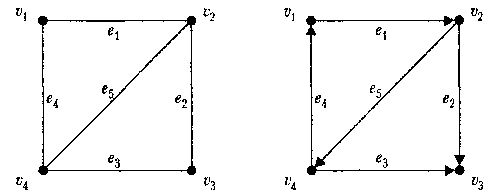
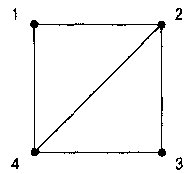
Рис. 10. Диаграммы графа (слева) и орграфа (справа), используемых в качестве примеров
Следует еще раз подчеркнуть, что конструирование структур данных для
представления в программе объектов математической модели —
это основа искусства практического программирования.
Мы приводим четыре различных базовых представления графов.
Выбор наилучшего представления определяется требованиями конкретной задачи.
Более того, при решении конкретных задач используются, как правило,
некоторые комбинации или модификации указанных представлений,
общее число которых необозримо.
Но все они так или иначе основаны на тех базовых идеях, которые описаны
в этом разделе.
Известны различные способы представления графов в памяти компьютера, которые различаются объемом занимаемой памяти и скоростью выполнения операций над графами. Представление выбирается, исходя из потребностей конкретной задачи. Далее приведены четыре наиболее часто используемых представления с указанием характеристики n(р, q) — объема памяти для каждого представления. Здесь р — число вершин, а q— число ребер.
| Замечание |
|---|
|
Указанные представления пригодны для графов и орграфов, а после некоторой
модификации также и для псевдографов, мультиграфов и гиперграфов. |
Представления иллюстрируются на конкретных примерах графа G и орграфа D, диаграммы которых представлены на рис. 10.
Представление графа с помощью квадратной булевской матрицы
М : array[1..p, 1..p] of 0..1,
отражающей смежность вершин, называется матрицей смежности,
где
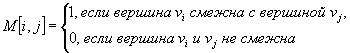
В матрице смежности на пересечении строки i и столбца j ставится 1, если вершины i и j - смежны, и 0 в противном случае.
В матрице смежности орграфа 1 ставится только в столбце j, номер которого соответствует вершине, в которую приxодит дуга из вершины i.
Пример
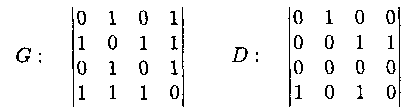
Представление графа с помощью матрицы Н : array
[1..p, 1..q] of 0..1
(для орграфов H :
array [1..p,1..q] of –1, 0, 1), отражающей инцидентность
вершин и ребер, называется матрицей инциденций,
где для неориентированного графа
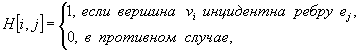
В матрице инциденций графа G каждое ребро отражается в столбце двумя единицами в тех строках, номера которых соответствуют вершинам, соединенным ребром.
а для ориентированного графа

Пример
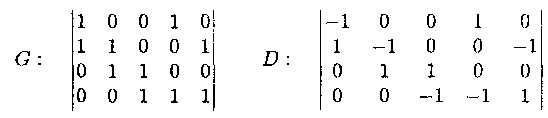
Представление графа с помощью списочной структуры, отражающей
смежность вершин и состоящей из массива указателей
Г : array [1..p] of
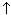 N на списки смежных вершин
(элемент списка представлен структурой N : record
v : 1..p; n :
N endrecord), называется
списком смежности.
В случае представления неориентированных графов списками смежности
N на списки смежных вершин
(элемент списка представлен структурой N : record
v : 1..p; n :
N endrecord), называется
списком смежности.
В случае представления неориентированных графов списками смежности
Пример
Списки смежности для графа G и орграфа D представлены на
рис. 11.
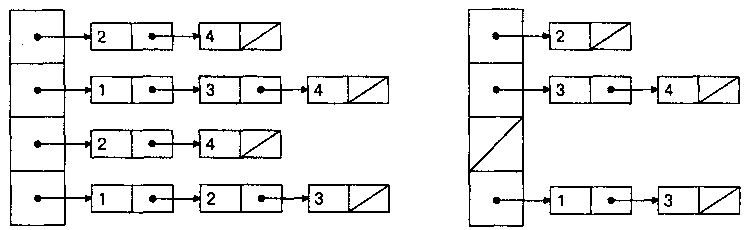
Представление графа с помощью массива структур
Е :
array [1..p] of record b,е: 1..p endrecord,
отражающего список пар смежных вершин, упорядоченный по возрастанию,
называется массивом ребер (или, для орграфов, массивом дуг).
Пример
Представление с помощью массива ребер (дуг) показано в следующей
таблице (для графа G слева, а для орграфа D справа).
Обход графа — это некоторое систематическое перечисление его вершин
(и/или ребер). Наибольший интерес представляют обходы, использующие
локальную информацию (списки смежности).
Среди всех обходов наиболее известны поиск в ширину и в глубину.
Алгоритмы поиска в ширину и в глубину лежат в основе многих конкретных
алгоритмов на графах.
|
Алгоритм 1. Поиск в ширину и в глубину Вход: граф G(V, Е), представленный списками смежности Г. Выход: последовательность вершин обхода. for v  V do
V dox[v] := 0 {вначале все вершины не отмечены} end for select v
V {начало обхода — произвольная вершина}v  T {помещаем v в структуру данных Т ... }
T {помещаем v в структуру данных Т ... }x[v] := 1 {... и отмечаем вершину v} repeat u  T{ извлекаем вершину из структуры данных Т ... }
T{ извлекаем вершину из структуры данных Т ... }yield u {... и возвращаем ее в качестве очередной пройденной вершины} for w
Г(u) doif x[w] = 0 then w
T {помещаем w в структуру данных Т ...}x[w] :=1 {... и отмечаем вершину w} end if end for until T = 
|
| Определение |
|---|
|
Если Т — это стек (LIFO — Last In First Out),
то обход называется поиском в глубину. Если T — это очередь (FIFO — First In First Out), то обход называется поиском в ширину. |
Пример
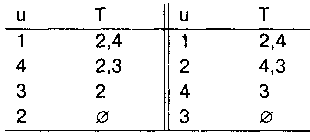
В следующей таблице показаны протоколы поиска в глубину и в ширину для графа,
диаграмма которого приведена на рис. 12.
Слева в таблице протокол поиска в глубину, а справа — в ширину.
Предполагается, что начальной является вершина 1.
| Теорема |
|---|
| Если граф G связен (и конечен), то поиск в ширину и поиск в глубину обойдут все вершины по одному разу. |
Доказательство
1. Единственность обхода вершины. Обходятся только вершины, попавшие в Т. В Г попадают только неотмеченные вершины. При попадании в Т вершина отмечается. Следовательно, любая вершина будет обойдена не более одного раза.
2. Завершаемость алгоритма. Всего в Т может попасть не более р вершин. На каждом шаге одна вершина удаляется из T. Следовательно, алгоритм завершит работу не более чем через р шагов.
3. Обход всех вершин. От противного. Пусть алгоритм закончил работу,
и вершина w не обойдена. Значит, w не попала в T.
Следовательно, она не была отмечена. Отсюда следует, что все вершины,
смежные с w, не были обойдены и отмечены.
Аналогично, любые вершины, смежные с неотмеченными, сами не отмечены
(после завершения алгоритма).
Но G связен, значит, существует путь <v, w>.
Следовательно, вершина v не отмечена.
Но она была отмечена на первом шаге!
| Следствие |
|---|
СЛЕДСТВИЕ Пусть (u1,..., ui,..., uj,...,
up) — обход (то есть последовательность вершин) при поиске в ширину.
Тогда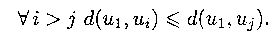 Другими словами, расстояние текущей вершины от начальной является монотонной функцией времени поиска в ширину, вершины обходятся в порядке возрастания расстояния от начальной вершины. |
| Следствие |
|---|
Пусть (u1,..., ui,..., up)
— обход при поиске в глубину. Тогда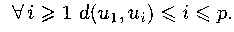 Другими словами, время поиска в глубину любой вершины не менее расстояния от начальной вершины и не более общего числа вершин, причем в худшем случае время поиска в глубину может быть максимальным, независимо от расстояния до начальной вершины. |
| Следствие |
|---|
Пусть (u1,..., ui,... , up) —
обход при поиске в ширину, a D (u1, 1),
D(u1, 2),... — ярусы графа относительно вершины
u1. Тогда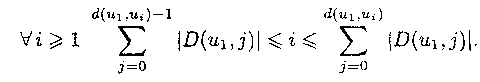 Другими словами, время поиска в ширину ограничено снизу количеством вершин во всех ярусах, находящихся на расстоянии меньшем, чем расстояние от начальной вершины до текущей, и ограничено сверху количеством вершин в ярусах, начиная с яруса текущей вершины и включая все меньшие ярусы. |
| Следствие |
|---|
|
Пусть (u1,..., ui,..., up)
— обход при поиске в ширину,
a (v1,..., vj,..., vp)
— обход при поиске в глубину, где ui = vj.
Тогда в среднем i = 2j. Другими словами, поиск в глубину в среднем вдвое быстрее, чем поиск в ширину. |