 = (аi
= (аi 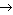
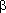 i)ni=1 — схема оптимального кодирования для распределения вероятностей Р = р1 >= … > = рn > 0. Тогда если рi > рj, то li < = lj.
i)ni=1 — схема оптимального кодирования для распределения вероятностей Р = р1 >= … > = рn > 0. Тогда если рi > рj, то li < = lj.
[Список тем] [Вступление к этой теме] Страницы темы: [1] [2]
Оптимальное кодирование обладает определенными свойствами, которые можно использовать для его построения.
| ЛЕММА |
|---|
| Пусть
= (аi
i)ni=1 — схема оптимального кодирования для распределения вероятностей Р = р1 >= … > = рn > 0. Тогда если рi > рj, то li < = lj.
|
Доказательство
От противного. Пусть i < j, рi > рj и li > 1j. Тогда рассмотрим
' = {a1
1, ..., аi
j, ..., аj
i, ..., аn
n}.
Имеем:
l
- l
' = (pili + рjlj) - (pilj + pjli) = (рi – рj)(li - lj) > 0,
что противоречит тому, что
— оптимально.
Таким образом, не ограничивая общности, можно считать, что li <=
… <= 1n.
| ЛЕММА |
|---|
|
Если
= (аi
i)ni=1 — схема оптимального префиксного кодирования для распределения вероятностей Р = р1 > = … >=
рn > 0, то среди элементарных кодов, имеющих максимальную длину, имеются два, которые различаются только в последнем разряде. |
Доказательство
От противного.
n = b, где b = 0 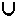 b = 1. Имеем:
b = 1. Имеем:
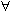 i
i
 1..n - 1 1i <= |
|. Так как схема префиксная, то слова 1, ...,
n-1 не являются префиксами . С другой стороны, не является префиксом слов 1, ..., n-1, иначе было бы = j, а значит,
j было бы префиксом n. Тогда схема ':= <а1
1, ..., аn
> тоже префиксная, причем l
'(Р) = l
(Р) – рn, что противоречит оптимальности
.
n-1 и
n максимальной длины отличаются не в последнем разряде, то есть n-1 =
'b', n =
"b", '
1..n - 1 1i <= |
|. Так как схема префиксная, то слова 1, ...,
n-1 не являются префиксами . С другой стороны, не является префиксом слов 1, ..., n-1, иначе было бы = j, а значит,
j было бы префиксом n. Тогда схема ':= <а1
1, ..., аn
> тоже префиксная, причем l
'(Р) = l
(Р) – рn, что противоречит оптимальности
.
n-1 и
n максимальной длины отличаются не в последнем разряде, то есть n-1 =
'b', n =
"b", '
 ", причем
', " не являются префиксами для 1, ..., n-2 и наоборот. Тогда схема ':= <а1
1, ..., аn-2
n-2, аn-1
'b', аn "> также является префиксной, причем l'(Р) = l
(Р) – рn, что противоречит оптимальности .
", причем
', " не являются префиксами для 1, ..., n-2 и наоборот. Тогда схема ':= <а1
1, ..., аn-2
n-2, аn-1
'b', аn "> также является префиксной, причем l'(Р) = l
(Р) – рn, что противоречит оптимальности .| Теорема |
|---|
|
Если
n-1 = (ai
i)n-1i=1 —
схема оптимального префиксного кодирования для распределения вероятностей
Р = р1 >= … >= рn-1 > 0 и рj =
q' + q", причем р1 >= … >= рj-1 >= рj+1 >= … >= рn-1 >= q' >= q" > 0, то кодирование со схемой n = (a1
1, ..., аj-1
j-1, аj+1
j+1, ..., an-1
n-1, aj
j0, an
j1)является оптимальным префиксным кодированием для распределения вероятностей Рn = p1, ..., рj-1, pj+1, ..., рn-1, q', q". |
Доказательство
n-1 было префиксным, то n тоже будет префиксным по построению.
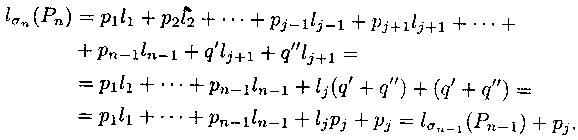
'n: = {аi
i}ni=1 оптимальна для Рn. Тогда по предшествующей лемме 'n = {a1
'1, ..., аn-2 'n-2, аn-1 0, аn 1}. Положим l' = || и рассмотрим схему
'n-1: = {а1
'1, ..., аj , ..., аn-2
'n-2}, где j определено так, чтобы рj-1 >= q' + q" >= рj+1.
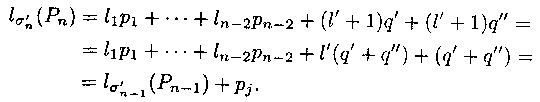
'nn - префиксное, значит,
'n-1 тоже префиксное.
'n - оптимально, значит, l
'n-1(Рn-1) >= l
n-1(Pn-1).
n(Рn) = l
n-1(Рn-1) + рj <=
l'n-1 (Рn-1) + pj = l'n(Рn), но
'n - оптимально, значит,
n оптимально.
Следующий рекурсивный алгоритм строит схему оптимального префиксного
алфавитного кодирования для заданного распределения вероятностей появления букв.
| Алгоритм Хаффмена |
|---|
|
Построение оптимальной схемы - рекурсивная процедура Huffman Вход: n - количество букв, Р : аrrау [1..n] of real - массив вероятностей букв, упорядоченный по убыванию. Выход: С : аrrау [1..n, 1..L] of 0..1 – массив элементарных кодов, l: аrrау [1..n] of 1..L –массив длин элементарных кодов схемы оптимального префиксного кодирования if n=2 then С[1,1]:= 0; l[1]:= 1{ первый элемент } С[2,1]:= 1; l[2]:=1{ второй элемент } else q:= Р[n - 1] + Р[n] { сумма двух последних вероятностей } j:= Uр(n, q) { поиск места и вставка суммы } Huffman (Р, n - 1) { рекурсивный вызов } Down (n, j) { достраивание кодов } end if |
|
Функция Uр находит в массиве Р место, в котором должно находиться число q (см. предыдущий алгоритм) и вставляет это число, сдвигая вниз остальные элементы. |
|
Вход: n — длина обрабатываемой части массива Р, q — вставляемая сумма. Выход: измененный массив Р. for i from n-1 downto 2 do if P[i-1] <= q then Р[i]:= P[i-1] { сдвиг элемента массива } else j:= i-1 { определение места вставляемого элемента } exit for i { все сделано — цикл не нужно продолжать } end if end for Р[j]: = q { запись вставляемого элемента } return j |
| Процедура Down строит оптимальный код для n букв на основе построенного оптимального кода для n - 1 буквы. Для этого код буквы с номером j временно исключается из массива С путем сдвига вверх кодов букв с номерами, большими j, а затем в конец обрабатываемой части массива С добавляется пара кодов, полученных из кода буквы с номером j удлинением на 0 и 1, соответственно. Здесь С'[i, *] означает вырезку из массива, то есть i-ю строку массива С. |
|
Вход: n — длина обрабатываемой части массива Р, j — номер “разделяемой” буквы. Выход: оптимальные коды в первых n элементах массивов С и l. с:= С[j, *]{ запоминание кода буквы j } l:= l[j] { и длины этого кода } for i from j to n-2 do C[i, *]:= С[i+1, *] { сдвиг кода } l[i]:= l[i+1] { и его длины } end for С[n-1, *]:= с; С[n, *]:= с{ копирование кода буквы j } С[n-1, l+1]:= 0; С[n, l+1]:= 1{ наращивание кодов } l[n-1]:= l+1; l[n]:= l + 1{ и увеличение длин } |
Обоснование
Для пары букв при любом распределении вероятностей оптимальное кодирование очевидно: первой букве нужно назначить код 0, а второй — 1. Именно это и делается в первой части оператора if основной процедуры Huffman. Рекурсивная часть алгоритма в точности следует доказательству теоремы предыдущего подраздела. С помощью функции Uр в исходном упорядоченном массиве Р отбрасываются две последние (наименьшие) вероятности, и их сумма вставляется в массив Р, так чтобы массив (на единицу меньшей длины) остался упорядоченным. Заметим, что при этом место вставки сохраняется в локальной переменной j. Так происходит до тех пор, пока не останется массив из двух элементов, для которого оптимальный код известен. После этого в обратном порядке строятся оптимальные коды для трех, четырех и т. д. элементов. Заметим, что при этом массив вероятностей Р уже не нужен — нужна только последовательность номеров кодов, которые должны быть изъяты из массива кодов и продублированы в конце с добавлением разряда. А эта последовательность хранится в экземплярах локальной переменной j, соответствующих рекурсивным вызовам процедуры Huffman.
Пример
Построение оптимального кода Хаффмена для n = 7. В левой части таблицы показано изменение массива Р, а в правой части — массива С. Позиция, соответствующая текущему значению переменной j, выделена полужирным начертанием.
| 0.20 | 0.20 | 0.23 | 0.37 | 0.40 | 0.60 | 0 | 1 | 00 | 01 | 10 | 10 |
| 0.20 | 0.20 | 0.20 | 0.23 | 0.37 | 0.40 | 1 | 00 | 01 | 10 | 11 | 11 |
| 0.19 | 0.19 | 0.20 | 0.20 | 0.23 | 01 | 10 | 11 | 000 | 000 | ||
| 0.12 | 0.18 | 0.19 | 0.20 | 11 | 000 | 001 | 010 | ||||
| 0.11 | 0.12 | 0.18 | 001 | 010 | 011 | ||||||
| 0.09 | 0.11 | 011 | 0010 | ||||||||
| 0.09 | 0011 |
Цена кодирования составляет
0.20 * 2 + 0.20 * 2 + 0.19 * 3 + 0.12 * 3 + 0.11 * 3 + 0.09 * 4 + 0.09 * 4 = 2.78,
что несколько лучше, чем в кодировании, полученном алгоритмом Фано.
[Список тем] [Вступление к этой теме] Страницы темы: [1] [2]