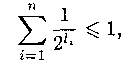 A*, то количество букв в слове называется длиной слова: α =
|а1 ... аk| = k. Пустое слово обозначается
A*, то количество букв в слове называется длиной слова: α =
|а1 ... аk| = k. Пустое слово обозначается
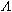 :
A*, || = 0,
:
A*, || = 0,
 A.
A.
[Список тем] [Вступление к этой теме] Страницы темы: [1] [2] [3]
Кодирование F может сопоставлять код всему сообщению из множества S как единому целому или же строить код сообщения из кодов его частей. Элементарной частью сообщения является одна буква алфавита A. Этот простейший случай рассматривается в этом и следующих двух разделах.
| Определение |
|---|
| Пусть задано конечное множество А = {a1, ..., аn}, которое называется алфавитом. Элементы алфавита называются буквами. Последовательность букв называется словом (в данном алфавите). |
Множество слов в алфавите А обозначается А*. Если слово
α = a1 ... аk
A*, то количество букв в слове называется длиной слова: α =
|а1 ... аk| = k. Пустое слово обозначается
:
A*, || = 0,
A.
| Определение |
|---|
|
Если α = α1α2.
то α1 называется началом, или префиксом, слова
α
, а α
2 — окончанием, или постфиксом, слова α. Если при
этом α1
(соответственно, α2
), то α1 (соответственно,
α2) называется собственным началом (соответственно,
собственным окончанием) слова α.
|
Алфавитное (или побуквенное) кодирование задается схемой (или таблицей кодов)
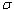 :
:= <а1
:
:= <а1 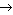
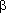 1, ..., аn
n>,
аi A,
i В*.
1, ..., аn
n>,
аi A,
i В*.
Множество кодов букв V:= { i }
называется множеством элементарных кодов.
Алфавитное кодирование пригодно для любого множества сообщений S:
F : А* В*,
аi1 ... аik = α
A*, F(α): =
i1 ... ik.
Пример
Рассмотрим алфавиты A: ={0,1,2,3,4,5,6,7,8,9}, В: ={0,1} и
схему
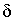 := <00,
11,
210,
311,
4100,
5101,
6110,
7111,
81000,91001>.
:= <00,
11,
210,
311,
4100,
5101,
6110,
7111,
81000,91001>.
Эта схема однозначна, но кодирование не является взаимно однозначным:
F(333) = 111111 = F(77),
а значит, невозможно декодирование. С другой стороны, схема
: = <00000,
10001,
20010,
30011,
40100,
50101,
60110,
70111,
81000,
91001>,
известная под названием “двоично-десятичное кодирование”, допускает
однозначное декодирование.
Рассмотрим схему алфавитного кодирования
и различные слова, составленные из элементарных кодов.
| Определение |
|---|
Схема называется разделимой, еслиi1 ...
ik = j1 ...
jl ==>
k = l & 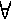 t
1 .. k it = jt, t
1 .. k it = jt,то есть любое слово, составленное из элементарных кодов, единственным образом разлагается на элементарные коды. Алфавитное кодирование с разделимой схемой допускает декодирование. |
Если таблица кодов содержит одинаковые элементарные коды, то есть если
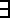 i, j i
i, j i 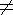 j &
i =
j,
j &
i =
j,
где i
j V, то схема заведомо не является
разделимой. Такие схемы далее не рассматриваются, то есть
i j
i,
j V ==>
i
j.
| Определение |
|---|
|
Схема называется префиксной, если элементарный код одной буквы не является
префиксом элементарного кода другой буквы:
( i j
i, j
V) ==> (
B* i
j). |
| Теорема |
|---|
|
Префиксная схема является разделимой. |
Доказательство
От противного. Пусть кодирование со схемой а не является разделимым.
Тогда существует такое слово
F(А*), что
=
i1 ... ik, =
j1 ...
jl & (t
s(s < t ==>
is = js &
it
jt)).
Поскольку it ...
ik = jt ...
jl, значит,
' (
it = jt
'  jt = jt
'), но это противоречит тому, что схема префиксная.
jt = jt
'), но это противоречит тому, что схема префиксная.
| Замечание |
|---|
| Свойство быть префиксной является достаточным, но не является необходимым для разделимости схемы. |
Пример
Разделимая, но не префиксная схема: А = {а, b}, В = {0,1},
= {а 0, b
01}.
Чтобы схема алфавитного кодирования была разделимой, необходимо, чтобы длины
элементарных кодов удовлетворяли определенному соотношению, известному как
неравенство Макмиллана.
| Теорема |
|---|
Если схема
= <аi
i>ni=1 разделила,
то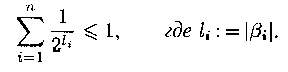 |
Доказательство
Обозначим
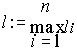
Рассмотрим n-ю степень левой части неравенства
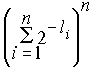
Раскрывая скобки, имеем сумму
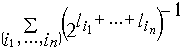
где i1, ..., in — различные наборы номеров
элементарных кодов. Обозначим через 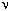 (n, t) количество входящих в эту сумму слагаемых вида 1/2t,
где t = li1 + … + lin. Для некоторых t может быть, что
(n, t) = 0. Приводя подобные, имеем сумму
(n, t) количество входящих в эту сумму слагаемых вида 1/2t,
где t = li1 + … + lin. Для некоторых t может быть, что
(n, t) = 0. Приводя подобные, имеем сумму
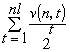
Каждому слагаемому вида (2Li1 + … + Lin)-1 можно
однозначно сопоставить код (слово в алфавите В) вида
i1 ...
in. Это слово состоит из п элементарных кодов и имеет длину t.
Таким образом,
(n, t) — это число некоторых слов вида
i1 ...
in, таких что |
i1 …
in| = t. В силу разделимости схемы
(n, t) <=
2t, в противном случае заведомо существовали бы два одинаковых
слова
i1 ...
in =
j1 ...
jn, допускающих различное разложение. Имеем
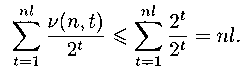
Следовательно,
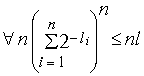
и значит,
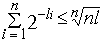 откуда
откуда
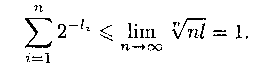
Неравенство Макмиллана является не только необходимым, но и в некотором смысле
достаточным условием разделимости схемы алфавитного кодирования.
| Теорема |
|---|
|
Если числа l1, ..., ln удовлетворяют неравенству то существует разделимая схема алфавитного кодирования
|
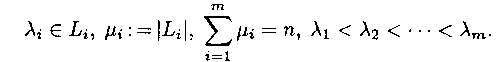
Тогда неравенство Макмиллана можно записать так:
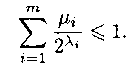
Из этого неравенства следуют т неравенств для частичных сумм:
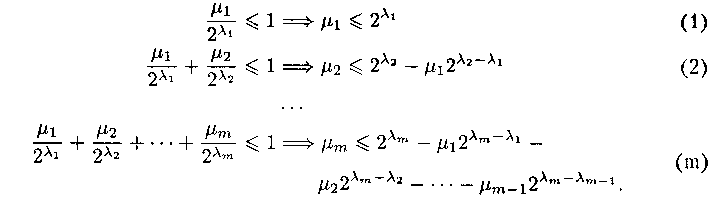
Рассмотрим слова длины
1 в алфавите В. Поскольку
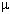 1 <= 2
1, из этих слов можно выбрать
1 различных слов
1, ...,
1 длины
1. Исключим из дальнейшего рассмотрения все слова из В*,
начинающиеся со слов
1, ...,
1. Далее рассмотрим множество слов в алфавите В длиной
2 и не начинающихся со слов
1, ...,
1. Таких слов будет 2
2 -
12
2-
1. Но
2 <= 2
2 -
12
2-
1, значит, можно выбрать
2 различных слов. Обозначим их
1+1, ...,
1+
2. Исключим слова, начинающиеся с
1+1, ...,
1+
2, из дальнейшего рассмотрения. И так далее, используя неравенства для
частичных сумм, мы будем на i-м шаге выбирать
i, слов длины
i,
1+
2+…+
i-1, ...,
1+
2+…+
i-1+
i, причем эти слова не будут начинаться с тех слов, которые были выбраны
раньше. В то же время длины этих слов все время растут (так как
1 <
2 < … <
m), поэтому они не могут быть префиксами тех слов, которые выбраны
раньше. Итак, в конце имеем набор из n слов
1, ...,
1+…+
m =
n, |
1| = l1, …, |
n| = ln, коды
1, ...,
n не являются префиксами друг друга, а значит, схема
= <аi
i>ni=1 будет префиксной и, по теореме
предыдущего подраздела, разделимой.
1 <= 2
1, из этих слов можно выбрать
1 различных слов
1, ...,
1 длины
1. Исключим из дальнейшего рассмотрения все слова из В*,
начинающиеся со слов
1, ...,
1. Далее рассмотрим множество слов в алфавите В длиной
2 и не начинающихся со слов
1, ...,
1. Таких слов будет 2
2 -
12
2-
1. Но
2 <= 2
2 -
12
2-
1, значит, можно выбрать
2 различных слов. Обозначим их
1+1, ...,
1+
2. Исключим слова, начинающиеся с
1+1, ...,
1+
2, из дальнейшего рассмотрения. И так далее, используя неравенства для
частичных сумм, мы будем на i-м шаге выбирать
i, слов длины
i,
1+
2+…+
i-1, ...,
1+
2+…+
i-1+
i, причем эти слова не будут начинаться с тех слов, которые были выбраны
раньше. В то же время длины этих слов все время растут (так как
1 <
2 < … <
m), поэтому они не могут быть префиксами тех слов, которые выбраны
раньше. Итак, в конце имеем набор из n слов
1, ...,
1+…+
m =
n, |
1| = l1, …, |
n| = ln, коды
1, ...,
n не являются префиксами друг друга, а значит, схема
= <аi
i>ni=1 будет префиксной и, по теореме
предыдущего подраздела, разделимой.
Пример:
Азбука Морзе — это схема алфавитного кодирования
<А
01, В
1000, С
1010, D
100, Е
0, F
0010, G
110, Н
0000, I
00, J
0111, К
101, L
0100, М
11, N
10, О
111, Р
0110, Q
1101, R
010, S
000, T
1, U
001, V
0001, W
011, Х
1001, Y
1011, Z
1100>,
где по историческим и техническим причинам 0 называется точкой и обозначается
знаком ″.″, а 1 называется тире и обозначается знаком “—”. Имеем:
1/4 + 1/16 + 1/16 + 1/8 + 1/2 + 1/16 + 1/8 + 1/16 + 1/4 + 1/16 + 1/8 + 1/16 + 1/4 + 1/4 + 1/8 + 1/16 + 1/16 + 1/8 + 1/8 + 1/2 + 1/8 + 1/16 + 1/8 + 1/16 + 1/16 + 1/16 = 2/2 + 4/4 + 7/8 + 12/16 = 3 + 5/8 > 1.
Таким образом, неравенство Макмиллана для азбуки Морзе не выполнено, и эта
схема не является разделимой. На самом деле в азбуке Морзе имеются
дополнительные элементы — паузы между буквами (и словами), которые позволяют
декодировать сообщения. Эти дополнительные элементы определены неформально,
поэтому прием и передача сообщений с помощью азбуки Морзе, особенно с высокой
скоростью, является некоторым искусством, а не простой технической процедурой.
[Список тем] [Вступление к этой теме] Страницы темы: [1] [2] [3]